文章目录
- 前言
- 考试题型
- 第一章、人工智能导引 (10分 )
-
- 课后习题
- 第二章、Python基础 (10分 )*
-
- 文件读写
- NumPy的使用
- Python绘图基础
- 第三章、机器学习初步(15分 )
-
- 逻辑回归分类(Logistic Regression)*,3.5
- 线性回归预测(Linear Regression)*,3.6 、3.7、 3.8
- 聚类 3.9
- 第四章、自然语言处理(10分 )
-
- 文本分词 与 词汇还原
- 文本分块* 与词袋模型 4.4、4.5
- 使用 TF-IDF算法* 构建文档类别预测器 4.6
- LDA
- 第五章、语音识别(10分 )
-
- 将音频信号从时域转换为频域* 5.2
- 生成音频信号 5.3
- 提取语音特征* ( MFCC,梅尔频率倒谱系数) 5.4
- 第六章、计算机视觉(10分 )
-
- 视频中移动物体检测方法
-
- 帧间差分法* 6.1
- 色彩空间跟踪对象 6.2
- 背景差分法 6.3
- 使用 CAMShift算法* 构建目标跟踪器 6.4
- 第七章、人工神经网络(20分 )
-
- 构建单层感知器*
- 单层与多层人工神经网络* 7.2 7.3
-
- 单层人工神经网络 7.2
- 多层人工神经网络 7.3
- 循环人工神经网络(Rerrent Neural Network, RNN) 7.4
- 第八章、强化学习和深度学习(15分 )
-
- 什么是深度学习
- 卷积神经网络
-
- 卷积运算*
- 使用单层神经网络建立图像分类器
- 使用卷积神经网络建立图像分类器
- 附录(常见英文)
前言

该篇序主要用于期末复习备考,便于初学者快速入门《人工智能导论》,可做参考。
考试题型
ß1选择题20分,每题1分,共20小题
ß2填空题20分,每题1分,共20小题
ß3简答题20分,每题4分,共5小题
ß4程序阅读理解题40分,每题8分,共5题
ß建议复习:
ß第3章,程序3.5-3.9
ß第4章,程序4.4-4.6
ß第5章,程序5.2-5.4
ß第6章,程序6.1-6.4
ß第7章,程序7.2-7.4
第一章、人工智能导引 (10分 )
学习任务:人工智能的概念,以及人工智能与大数据、机器学习、深度学习的联系等。
- 人工智能的概念
人工智能(Artificial Intelligence) ,它研究、开发用于模拟、延伸和扩展人的智能,是计算机科学的一个研究分支。
人工智能的研究是从以“推理”为重点到以“知识”为重点,再到以“学习”为重点
- 人工智能与大数据
大数据不断驱动人工智能的发展。大数据应用的人工智能技术:
- 外推
- 异常检测
- 贝叶斯原理
- 人工智能与机器学习
机器学习是实现人工智能的一个途径,即以机器学习为手段,解决人工智能中的问题。
机器学习就是设计一个算法模型来处理数据,我们可以针对算法模型进行不断的调优,形成更准确的数据处理能力。机器学习与统计学联系尤为密切,也被称为统计学习理论。
机器学习的应用:数据挖掘、数据分类、计算机视觉、自然语言处理(NLP)、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别
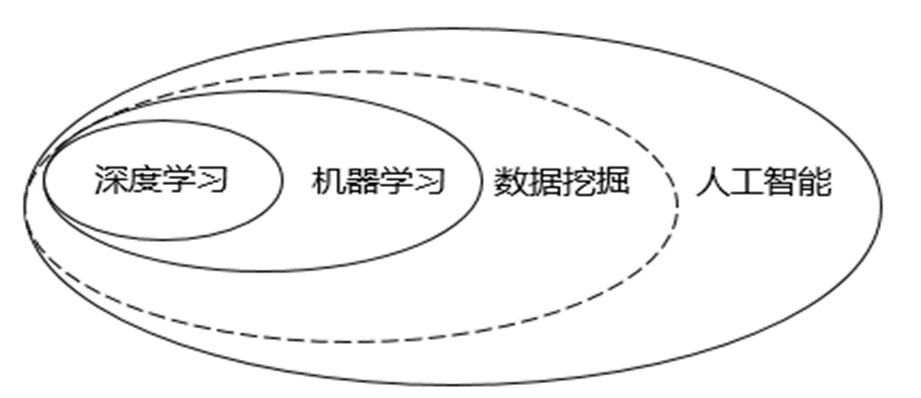
- 人工智能与深度学习
深度学习是机器学习中一种基于对数据进行表征学习的方法。它是机器学习中的神经网络算法的延伸,可以理解为包含很多个隐层的神经网络模型,是机器学习中最热门的算法
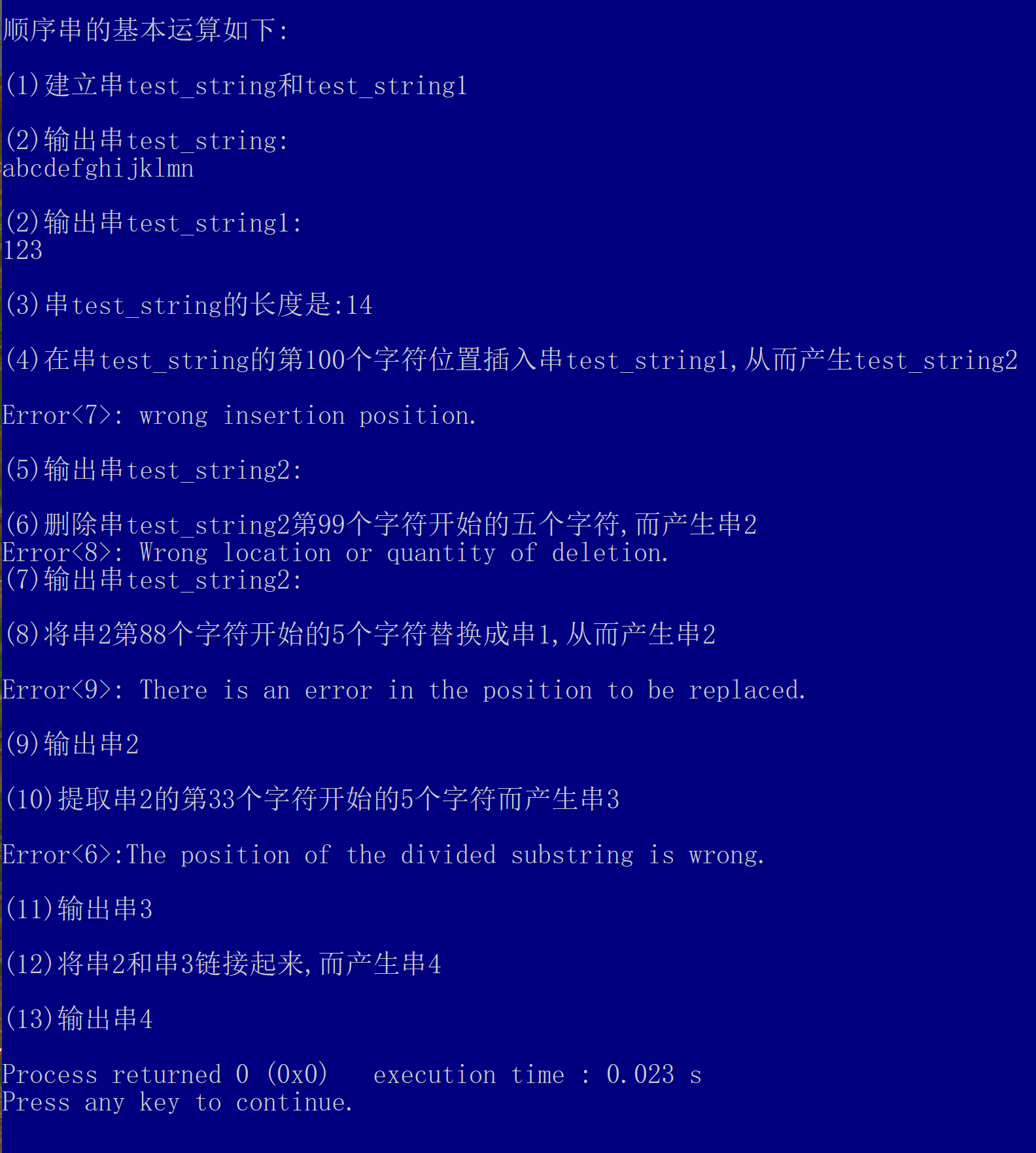
课后习题
- 人工智能是什么?
人工智能是一门基于计算机科学、生物学、心理学、神经科学、数学和哲学等学科的科学
- 人工智能怎么来的?
人工智能是基于图灵测试,随着第一个可编程机器人的发明、人工智能诞生
- 大数据与人工智能的关系
人工智能可以用传统上人类无法处理的方式处理大数据集。随着数字经济的不断扩大,大数据不断地驱动人工智能的发展,主要表现为建立驱动数据和知识引导的智能计算平台和方法,形成从数据到知识、从知识到智慧这样一个逐步上升的过程
- 大数据应用的人工智能技术
外推、异常检测、叶贝斯原理
- 人工智能与机器学习
机器学习是人工智能的一个分支研究领域,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
机器学习是实现人工智能的一个途径,即以机器学习为手段解决人工智能中的问题
- 人工智能与深度学习
深度学习是机器学习中的一种基于对数据进行表征学习的方法。他使得机器学习能够实现众多应用,并拓展了人工智能的领域范围,是实现机器学习的技术。他是机器学习中神经网络算法的延伸,可以理解为包含多个隐层的神经网络模型;也是机器学习中最热门的算法,在图像、语音等富媒体的废了计划识别上取得了非常好的效果。
深度学习也很好的实现了各种任务,使得似乎所有机器辅助功能都变为可能。
- 什么是人工智能!]?试从学科和能力两方面加以说明。
从学科角度来看:人工智能是计算机科学中涉及研究、设计和应用智能机器的一个分支。它的近期主要目标在于研究用机器来模仿和执行人脑的某些智能功能,并开发相关理论和技术。
从能力角度来看:人工智能是智能机器所执行的通常与人类智能有关的功能,如判断、 推理、 证明、识别、感知、理解、设计、思考、规划、学习和问题求解等思维活动
- 在人工智能的发展过程中,有哪些思想和思潮起了重要作用? *
控制论之父维纳 1940年主张计算机五原则。他开始考虑计算机如何能像大脑一样工作。系 统地创建了控制论,根据这-理论,一个机械系统完全能进行运算和记忆。
帕梅拉·麦考达克(Pamela McCorduck)在她的著名的人工智能历史研究《机器思维》(Machine Who Think,1979)中曾经指出:在复杂的机械装置与智能之间存在着长期的联系。著名的英国科学家图灵被称为人工智能之父,图灵不仅创造了一个简单的通用的非数字计算模型,而且直接证明了计算机可能以某种被理解为智能的方法工作。提出了著名的图灵测试。数理逻辑从19 世纪末起就获迅速发展;到 20 世纪 30 年代开始用于描述智能行为。计机 出现后,又在计算机上实现了逻辑演绎系统。
1943年由生理学家麦卡洛克(McCuloch)和数理逻辑学家皮茨(Pitts)创立的脑模型,即MP模 型。60-70年代,联结主义,尤其是对以感知机(perceptron)为代表的脑模型的研究曾出现过热潮,
控制论思想早在 40-50 年代就成为时代思潮的重要部分,影响了早期的人工智能工作者。到60-70 年代,控制论系统的研究取得一定进展,播下智能控制和智能机器人的种子。
- 人工智能有哪些研究领域和应用领域? *
(1) 研究领域:自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计,软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法
(2) 应用领域:智能控制,机器人学,语言和图像理解,遗传编程,头像识别,语语音识别
第二章、Python基础 (10分 )*
学习任务:文件读写、NumPy的使用、Python绘图基础
文件读写
- 获取文件路径:
绝对路径:从根目录开始
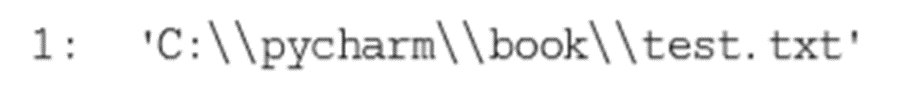
相对路径:相当于程序的当前工作目录

- 读文件
先调用open()函数打开文件,再调用read()读取文件,最后调用close()关闭文件。
代码示例:
f = open ('exam.txt','r',encoding='utf-8')
print(f.read())
f .close()
文件读取时报错的解决方式:
1. 使用try…except… finally错误处理机制;
try:
f = open('test.txt','r')
print(f.read)
finally:
f.close()
2. 通过with语句自动调用close()方法。
with open('test.txt','r') as f:
print(f.read))
文件读取方式:

- 写文件
代码示例:
f = open ('exam.txt','w',encoding='utf-8')
f.write ('Hello Python')
f .close()
with open('test.txt','w') as f:
f.write('Hello Python')
NumPy的使用
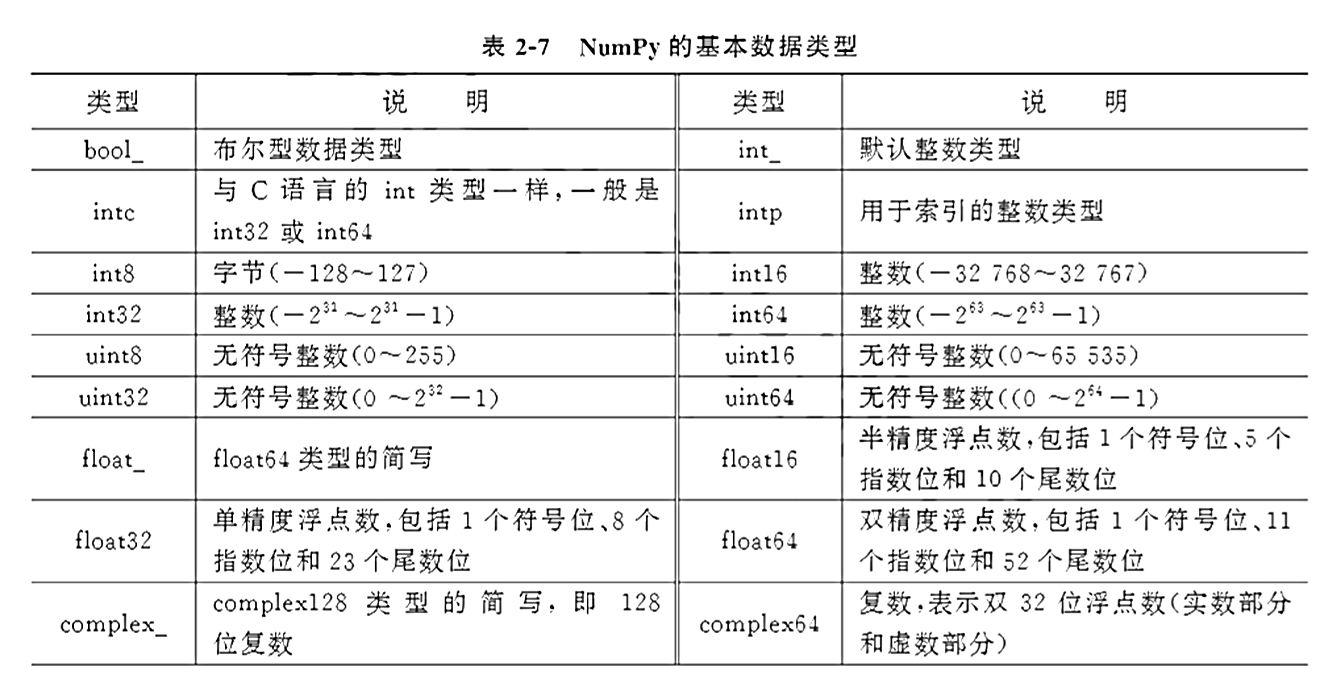
安装命令: pip install NumPy
数据类型:
创建数组函数:
numpy.empty() 方法可以创建一个指定形状、数据类型且未初始化的数组。使用numpy.empty()方法创建的数组通常数组内元素为空,没有实际意义,所以也是创建数组方法中 最快 的一种。
numpy.zeros() 方法可以创建指定大小的数组,数组元素以0填充。
numpy.ones() 方法可以创建指定形状的数组,数组元素以1填充。
numpy.asarray() 方法可以将结构数据转换为多维数组(ndarray),并且不会占用新的内存。
numpy.fromBuffer() 方法可以用于实现动态数组,接收buffer 输入参数,以流的形式读入并转换为 ndarray对象。
numpy.fromiter() 方法可以从可迭代对象中建立 ndarray 对象,返回一维数组。
numpy.arange(start, stop, step),在给定的范围[start,stop)内,返回间隔(step)均匀的值。
numpy.linespace(start, stop, num=50),在给定间隔内,返回num(默认50)个)均匀分布的数字。
numpy.logspace() 方法可以用于创建一个等比数列。
import numpy as np
x = np.arange(10,50,8)
y = np.logspace(0,4,5,base = 2) # linspace() 方法
print(y)
print (x)
-----
[10 18 26 34 42]
[1. 2. 4. 8. 16.]
数组索引:
- 使用 slice() 函数切割函数
- 通过冒号分隔切片参数 start : stop : step进行切片
代码示例:
import numpy as np
a = np.arange(10) # 0 1 2 3 4 5 6 7 8 9,arange 从 0开始 生成10个整数
x1 = slice (1,9,3) #从索引1开始到索引8停止 间隔为3
x2 = a [2:8:2] #从索引2开始到索引7停止 间隔为 2
print (a[x1],'\n',x2)
结果:
[1 4 7]
[2 4 6]
高级索引
import numpy as np
import numpy as np
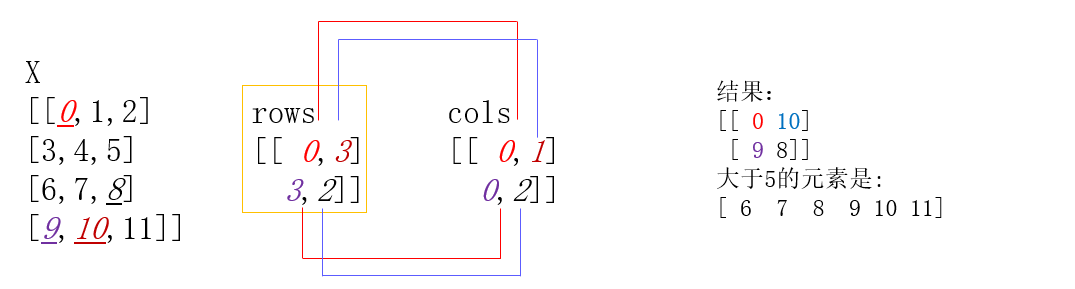
x = np.array([[0,1,2],[3,4,5],[6,7,8],[9,10,11]])
rows = np.array([[0,3],[3,2]])
cols = np.array([[0,1],[0,2]])
y = x [rows,cols]
print (y)
print ('大于5的元素是:') #打印出大于5的元素,布尔索引
print (x[x>5])
----
结果:
[[ 0 10]
[ 9 8]]
大于5的元素是:
[ 6 7 8 9 10 11]
解释:
y 中的值应该结合 rows 和 cols 一起看,
第一个数组的第一个数 为 rows 的第一个数 0 ,和 cols的第一个数 0,则 y 第一个数组的第一个数为 x的 第 0 行 第 0 列 的数字 ,即 0;
第一个数组的第二个数 为 rows 的第二个数 3 ,和 cols的第二个数 1,则 y 第一个数组的第二个数为 x的 第 3行 第 1 列 的数字 , 即 10;
数组操作
- 修改数组的形状
numpy.reshape()函数 可以在不改变数据的条件下修改数组形状。
numpy.ndarray.flatten(C/F/A)函数 返回一份数组副本,对副本所做的修改不会影响原始数组。其中,C表示按照 行填充;F 表示 按照列填充;A 表示按照原顺序填充;默认为 C 。
-
翻转数组
numpy.transpose()函数 用于对换数组的维度。
numpy.rollaxis()函数 向后滚动特定的轴到一个特定位置。
numpy.swapaxes()函数 用于交换数组的两个轴。 -
修改数组维度
numpy.broadcast_to()函数将数组广播到新形状,在原始数组上返回只读视图。它通常不连续,如果新形状不符合 NumPy 的广播规则,该函数可能会抛出ValueError。 -
连接数组
-
分割数组
-
数组元素的添加与删除
Python绘图基础
初级绘图
- 引入第三方库:在Python中使用任何第三方库时,都必须先将其引入。
import matplotlib.pyplot as plt 或者: from matplotlib.pyplot import *
- 建立空白页
fig = plt.figure()
指定空白页大小
fig = plt.figure (figsize= (4,2))
- 基础绘图
import matplotlib.pyplot as plt
plt.plot ([1,3,2,4],[1,2,3,4]) # 折线图
plt.show()
- plt.plot----折线图
- plt.bar----条形图,柱状图(有间隔,数据为离散型)
- plt.hist----直方图(无间隔,数据为连续型)
线条
-
线条属性

-
线条标记
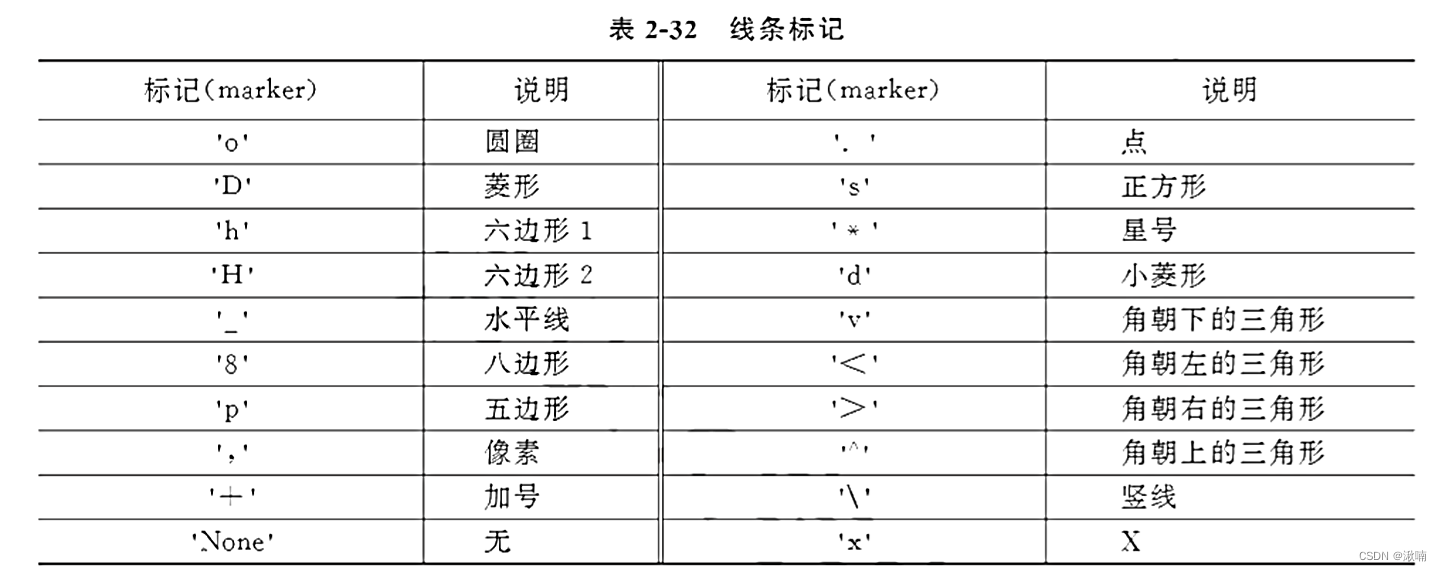
-
线条颜色
可以通过调用matplotlib.pyplot.colors()得到Matplotlib支持的8种颜色,如果这8种基础颜色不够用,还可以通过两种其他方式定义颜色值:
(1) 使用HTML十六进制字符串: color=‘eeefff’
(2) 传入一个归一化到[ 0, 1]的RGB元组: color=(0.9,0.,0.8)
通过设置plt.plot()函数的参数color(或等效的简写为c),可以设置曲线的颜色。
import numpy as np
import matplotlib.pyplot as plt
def pdf(x,mu,sigma):
a=1./(sigma*np.sqrt(2.*np.pi))
b=-1./(2.*sigma**2)
return a*np.exp(b*(x-mu)**2)
x=np.linspace(-6,6,1000)
plt.plot(x,pdf(x,0.,1.),color='#00ff00')
plt.plot(x,pdf(x,0.4,1.),color=(0.9,0.,0.8))
plt.show()
- 线条粗细
线条粗细使用linewidth设置,对应线条上的marker大小设置为ms参数。
如果想要marker为空心,可以在后面加上markerfacecolor=‘none’。
plt.plot (y,'bx--',y+1,'yo',linewidth=4.0)
plt.plot (y+2,'kp-',y+3,'rD-',ms=8)
plt.plot (y+2,'kp-',y+3,'rD-',ms=8,markerfacecolor='none')
第三章、机器学习初步(15分 )
逻辑回归分类(sigmoid函数、损失函数)
线性回归预测(拟合数据)
聚类
机器学习工作流程:
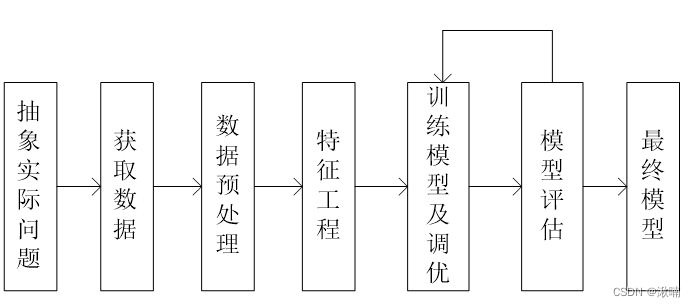
- 抽象实际问题: 深入理解实际问题的业务场景是机器学习的开始。理解实际问题,主要包括明确可以获得的数据,明确机器学习的目标是分类、回归还是聚类。
- 获取数据:在获取数据时,得到的数据要有代表性
- 数据预处理:实际的场景中,得到的数据常常并不满足机器学习算法的要求。比如,性别数据的缺失、年龄数据的异常(输入造成的负数或者超大的数)。因此通常都需要对数据进行基本处理,包括数据清洗、数据归一化、扩充等。
- 特征工程:特征工程包括从原始数据中进行特征构建、特征提取和特征选择。
- 训练模型和调优:根据数据的实际情况和具体要解决的问题来选择模型。
数据:样本数、特征维度、数据特征;
模型调优:交差验证、观察损失曲线、测试结果曲线等方法来分析,可以整合多个模型,提高学习效果。
- 模型评估:根据分类、回归等不同的问题,选择不同的评价指标,评估模型的准确率、误差、时间复杂度、空间复杂度、稳定性、可迁移性等。
机器学习分类:
-
有监督学习(supervised learning):给定数据,有标签,有反馈,预测未来结果(标签)。
-
无监督学习(Unsupervised learning):给定数据,无标签,无反馈,寻找隐藏的结构(自动聚类)
特点:
- ⑴ 无监督学习没有明确的目的
- ⑵ 无监督学习不需要给数据打标签
- ⑶ 无监督学习无法量化效果
应用:
- ⑴ 用户细分
- ⑵ 推荐系统
- 强化学习(Reinforcement Learning):主要由智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)组成。
例如:学英语。有监督学习是先读几篇中英文对照的文章,从而学会阅读和理解纯英语的文章。无监督学习是直接阅读大量纯英文文章,当数量达到一定程度,虽然不能完全理解文章,但也会发现一些词组的固定搭配,句式等等。
不同:
a) 监督学习 是最常见的一种机器学习,它的训练数据是有标签的,训练目标是能够给新数据(测试数据)以正确的标签。例如,将邮件进行是否垃圾邮件的分类,一开始我们先将一些邮件及其标签(垃圾邮件或非垃圾邮件)一起进行训练,学习模型不断捕捉这些邮件与标签间的联系进行自我调整和完善,然后给一些不带标签的新邮件,让该模型对新邮件进行是否是垃圾邮件的分类。
b) 无监督学习 常常被用于数据挖掘,用于在大量无标签数据中发现些什么。它的训练数据是无标签的,训练目标是能对观察值进行分类或者区分等。例如无监督学习应该能在不给任何额外提示的情况下,仅依据所有“猫”的图片特征,将“猫”的图片从大量的各种各样的图片中将区分出来。
c) 强化学习 通常被用在机器人技术上(例如机械狗),它接收机器人当前状态,算法的目标是训练机器来做出各种特定行为。工作流程:机器被放置在一个特定环境中,在这个环境里机器可以持续性地进行自我训练,而环境会给出正或负的反馈。机器会从以往的行动经验中不断得到提升,并最终找到最好的知识内容来帮助它做出最有效的行为决策。
数据预处理:
- 数据清洗:将数据集的“脏”数据去除(如网页上爬取的内容不完整的数据记录)
- 数据变换:对数据的规范化、离散化或稀疏化处理。规范化是对数据进行归一化和 标准化;离散化是将取值的连续区间划分为小的区间,再将每个小区间重新定义为一个唯一的取值;稀疏化是进行数据抽样,如对图模型中的结点和边分别进行数据抽样(疏化处理),然后对疏化处理的结果进行图聚类分析。
- 数据过滤:对数据集处理前,对数据某些属性(字段)进行过滤。
逻辑回归分类(Logistic Regression)*,3.5
逻辑回归主要解决的是二分类的问题,即分类的结果只有两个类别。属于判别式的线性分类模型——就是直接根据数据进行参数估计的模型。
逻辑回归的应用场景如:基于邮件的特征,去判断一封邮件是否是垃圾邮件;基于用户行为,判断用户的性别等。
Sigmoid 函数 通过与0.5的比对得出数据所属的分类,大于0.5的概率则判别为1,小于0.5的概率则判别为0。
函数形式为: s i g m o i d ( z ) = 1 1 + e − x sigmoid (z) = \frac{1}{1+e^{-x}} sigmoid(z)=1+e−x1

示例代码:
from sklearn. datasets import load_iris
import pandas as pd
from sklearn. linear_model import LogisticRegression
# 导入所需的库和模块
from sklearn.datasets import load_iris # 加载鸢尾花数据集
import pandas as pd # 数据处理和分析库
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集的函数
# 加载鸢尾花数据集
iris = load_iris()
# 提取数据集中的特征和目标变量
x = iris.data
y = iris.target
# 划分训练集和测试集,测试集占比为20%
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0, test_size=0.20)
# 创建逻辑回归模型,使用牛顿共轭梯度法求解,多类分类模式为多项式分布
clf = LogisticRegression(C=1, solver='newton-cg', multi_class='multinomial')
# 在训练集上拟合模型
clf.fit(x_train, y_train)
# 输出实际值和预测值
print("实际值:", y_test)
print("预测值:", clf.predict(x_test))
# 输出训练集和测试集上的准确率得分
print(clf.score(x_train, y_train))
print(clf.score(x_test, y_test))
# 预测新数据点的分类结果
print(clf.predict([[3.1, 2.3, 1.2, 0.5]]))
-------
实际值: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1



![[开源软件] 支持链接汇总](https://img-blog.csdnimg.cn/direct/35ae3fb6261f492c922962d642e62666.png)